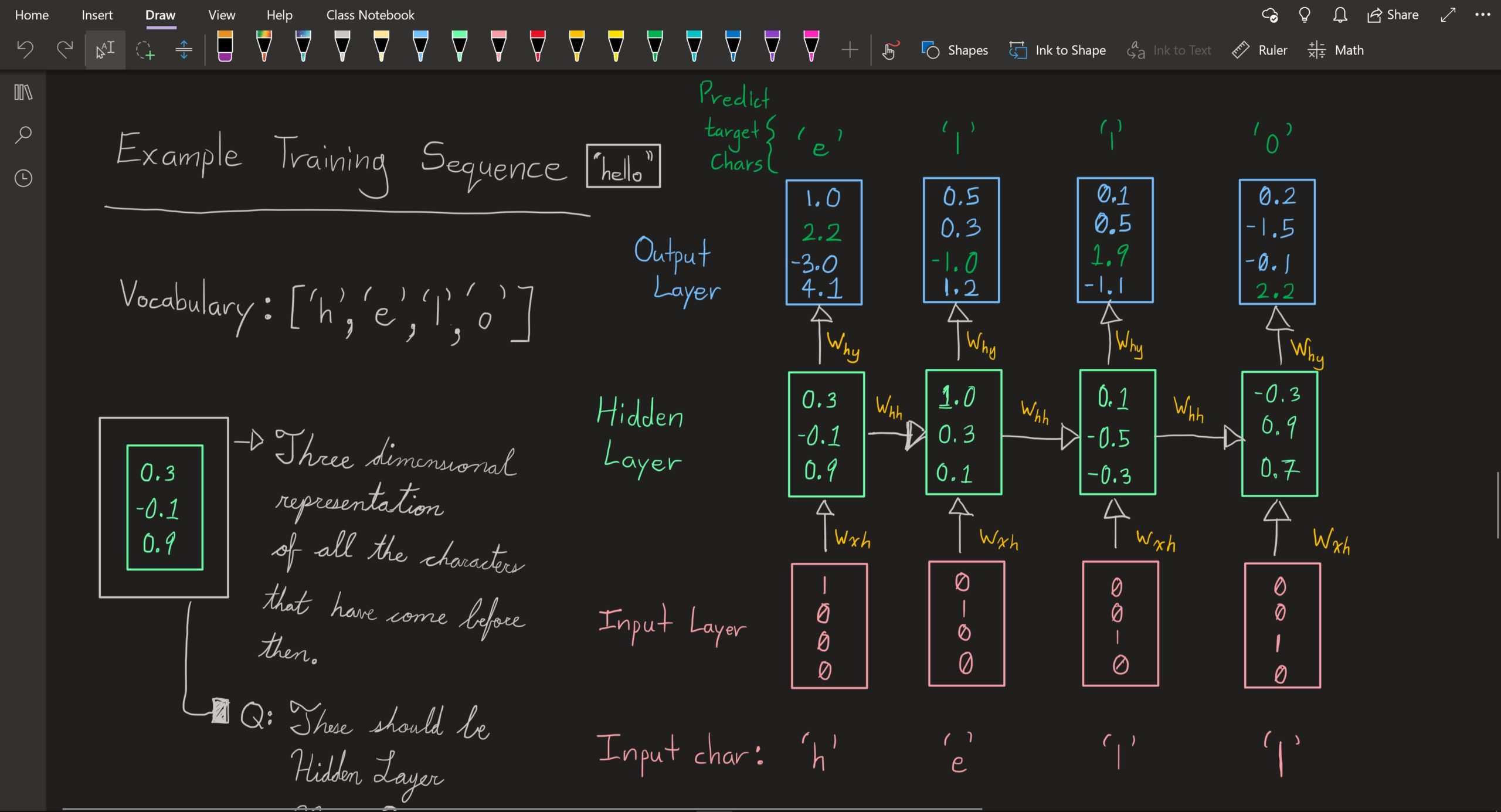
Today was a solid day of work on learning Recurrent Neural Networks (RNNs). I drew some diagrams, took some notes, and asked a lot of questions about how the current example is structured. The current example I am working on is a character prediction RNN where, at each time step ‘t’ it should predict the next character in the word/sentence.
So here are some of my questions:
- The diagrams I have seen, represent the hidden layer of the RNN at each time step with what appears to be only one neuron. Is that actually the case? I mean that doesn’t make sense so I drew out what I imagine it to be when it is expanded upon.
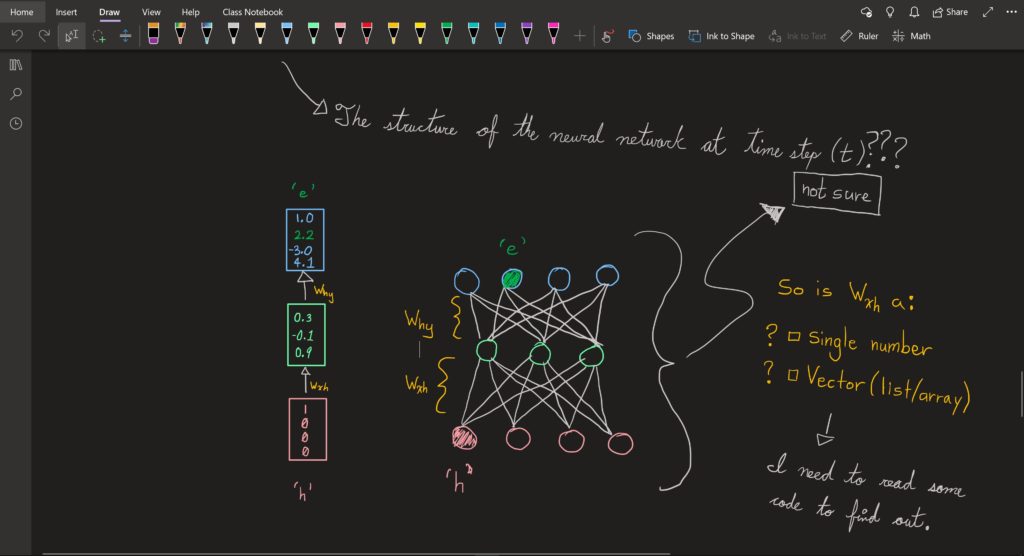
- The weights applied between different layers in the RNN at each time step seem to be one value. Is that really the case? Wouldn’t they realistically be a vector (an object with multiple values i.e. [ 0, 0.5, 2.6, -1, 0.3 ])
- How does the output from the previous hidden layer get applied at time step ‘t + 1’ with the associated weight ‘W_hh’ ?
I made a reasonable amount of progress and I am excited to get working through the actual code for this example. Thankfully Andrej had posted it up on his GitHub and also wrote a blog about it.
Btw, I took a quick peak; 100 hidden layer size is what I saw with the initialization! My diagram is way too small. I can’t wait to break this code down thoroughly.
