I have been reading up on how to approach algorithms and data structures. I previously thought I could get better by repeatedly solving problems. I didn’t have a ton of success with that approach so it seemed like I needed to change. My current view is to pursue a clear understanding of why a certain data structure is used to solve a specific problem. From my experience, I tend to value and remember things when I know how and why they are important. So today was the start of this more in depth journey into understanding data structures and algorithms within the scope of their actual application and benefits in real world computer processing situations.
TLDR;
Okay, so here are the highlights of what I did:
- I finished watching the Lecture 6 YouTube video for the MIT Missing Semester Course. I probably need to re-watch this video a few times before it sinks in. Git in the terminal looks a bit tricky even though I am already familiar with Git.
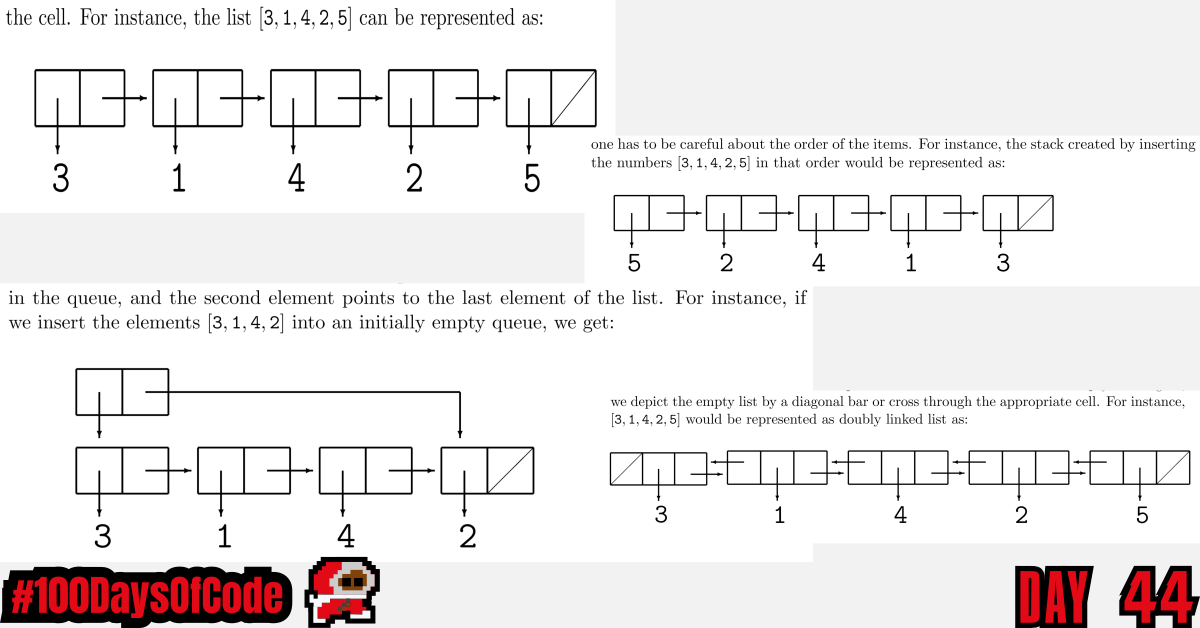
- Read through chapters 2 & 3 from the ‘Lecture Notes for Data Structures and Algorithms’ by John Bullinaria. It covered some basic programming procedures like loops, conditionals, and then covered arrays, lists, queues, stacks, and doubly linked lists. I somewhat understood the baseline differences. Learning a bit about Assembly code helped me put the reality of storage space into context when learning about different types of data structures and declaring storage sizes. I am still only scratching the surface but it’s a start.
- I went through a few more
awkexamples and learned about the defaultFSvalues andOFSvalues. I think I need to read through section 5 of the manual that coverprintfin detail. The baselineprinttool is great but also a bit limiting. - Read a great article on how to approach data structures and algorithms for tech job interviews.
Notes on awk
The Field Separator Value (FS)
FS contains the field separator character which is used to divide fields on the input line. The default is “white space”, meaning the white apce character. FS can be reassigned to another character (typically in BEGIN) to change the field separator. By default all leading white space is ignored but when the FS is changed from a single “white space” to any other value those leading white spaces will be considered.
$ printf ' a ate b\tc \n'
a ate b c
$ printf ' a ate b\tc \n' | awk '{print $1}'
a
$ printf ' a ate b\tc \n' | awk '{print NF}'
4
$ # same behavior if FS is assigned to single space character
$ printf ' a ate b\tc \n' | awk -F' ' '{print $1}'
a
$ printf ' a ate b\tc \n' | awk -F' ' '{print NF}'
4
$ # for anything else, leading/trailing whitespaces will be considered
$ printf ' a ate b\tc \n' | awk -F'[ \t]+' '{print $2}'
a
$ printf ' a ate b\tc \n' | awk -F'[ \t]+' '{print NF}'
6
Assigning FS to an empty string will split the fields by every single character. That’s kind of crazy and not used very often. Maybe it could be useful in some instances.
Conclusion
That’s all for today. If you are interested in the MIT course you can check out the video lecture I’m currently going through. The lecture is helpful but isn’t sufficient by itself. Anyways, until next time PEACE!